Portfolio item number 1
Short description of portfolio item number 1

Short description of portfolio item number 1
Short description of portfolio item number 2
Published in Advances in Neural Information Processing Systems 34 (NeurIPS 2021), 2021
In image retrieval, standard evaluation metrics rely on score ranking, e.g. average precision (AP). In this paper, we introduce a method for robust and decomposable average precision (ROADMAP) addressing two major challenges for end-to-end training of deep neural networks with AP: non-differentiability and non-decomposability. Firstly, we propose a new differentiable approximation of the rank function, which provides an upper bound of the AP loss and ensures robust training. Secondly, we design a simple yet effective loss function to reduce the decomposability gap between the AP in the whole training set and its averaged batch approximation, for which we provide theoretical guarantees. Extensive experiments conducted on three image retrieval datasets show that ROADMAP outperforms several recent AP approximation methods and highlight the importance of our two contributions. Finally, using ROADMAP for training deep models yields very good performances, outperforming state-of-the-art results on the three datasets. Code and instructions to reproduce our results will be made publicly available at github.com/elias-ramzi/ROADMAP.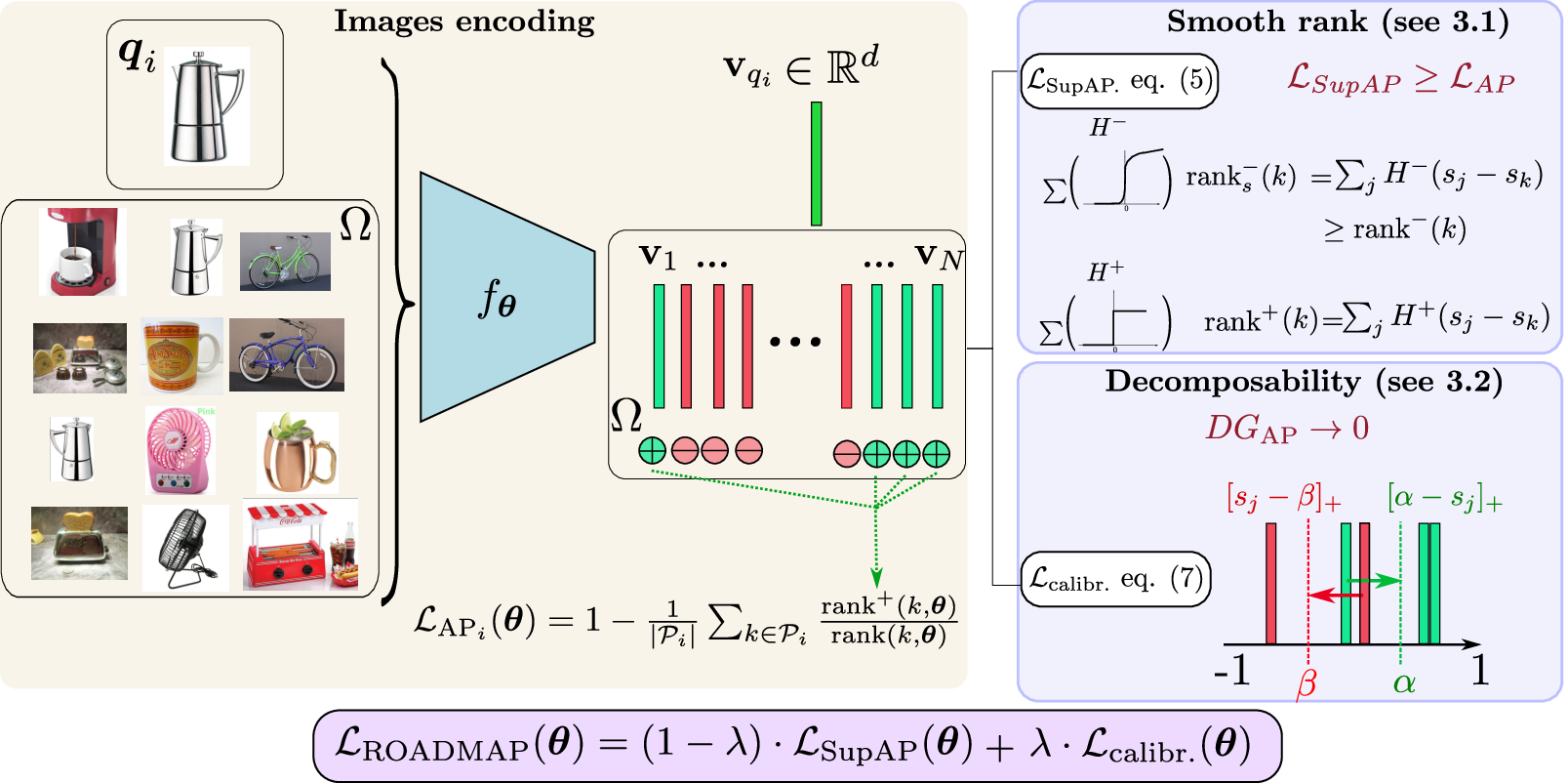
Recommended citation: Elias Ramzi, Nicolas Thome, Clément Rambour, Nicolas Audebert, Xavier Bitot: Robust and decomposable average precision for image retrieval. Advances in Neural Information Processing Systems 34 (NeurIPS, 2021). https://arxiv.org/abs/2110.01445
Published in European Conference on Computer Vision (ECCV 2022), 2022
Image Retrieval is commonly evaluated with Average Precision (AP) or Recall@k. Yet, those metrics, are limited to binary labels and do not take into account errors’ severity. This paper introduces a new hierarchical AP training method for pertinent image retrieval (HAPPIER). HAPPIER is based on a new H-AP metric, which leverages a concept hierarchy to refine AP by integrating errors’ importance and better evaluate rankings. To train deep models with H-AP, we carefully study the problem’s structure and design a smooth lower bound surrogate combined with a clustering loss that ensures consistent ordering. Extensive experiments on 6 datasets show that HAPPIER significantly outperforms state-of-the-art methods for hierarchical retrieval, while being on par with the latest approaches when evaluating fine-grained ranking performances. Finally, we show that HAPPIER leads to better organization of the embedding space, and prevents most severe failure cases of non-hierarchical methods. Our code is publicly available at github.com/elias-ramzi/HAPPIER.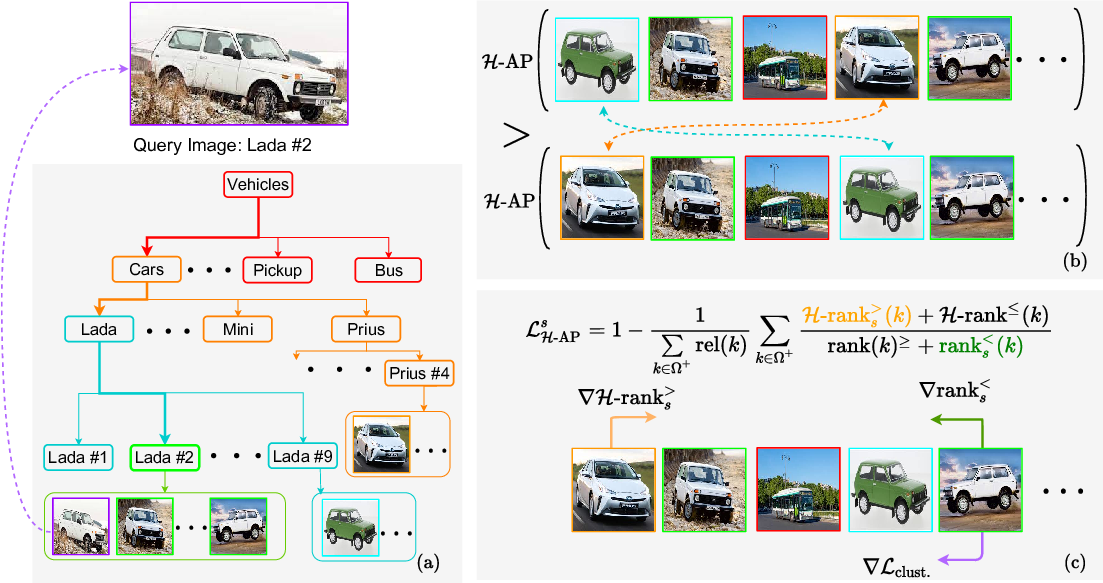
Recommended citation: Elias Ramzi, Nicolas Audebert, Nicolas Thome, Clément Rambour, Xavier Bitot: RHierarchical Average Precision Training for Pertinent Image Retrieval. In: European Conference on Computer Vision. Springer (ECCV, 2022). https://arxiv.org/abs/2207.04873
Published in International Conference on Machine Learning (ICML 2023), 2023
Out-of-distribution (OOD) detection is a critical requirement for the deployment of deep neural networks. This paper introduces the HEAT model, a new post-hoc OOD detection method estimating the density of in-distribution (ID) samples using hybrid energy-based models (EBM) in the feature space of a pre-trained backbone. HEAT complements prior density estimators of the ID density, e.g. parametric models like the Gaussian Mixture Model (GMM), to provide an accurate yet robust density estimation. A second contribution is to leverage the EBM framework to provide a unified density estimation and to compose several energy terms. Extensive experiments demonstrate the significance of the two contributions. HEAT sets new state-of-the-art OOD detection results on the CIFAR-10 / CIFAR-100 benchmark as well as on the large-scale Imagenet benchmark. The code is available at: github.com/MarcLafon/heatood.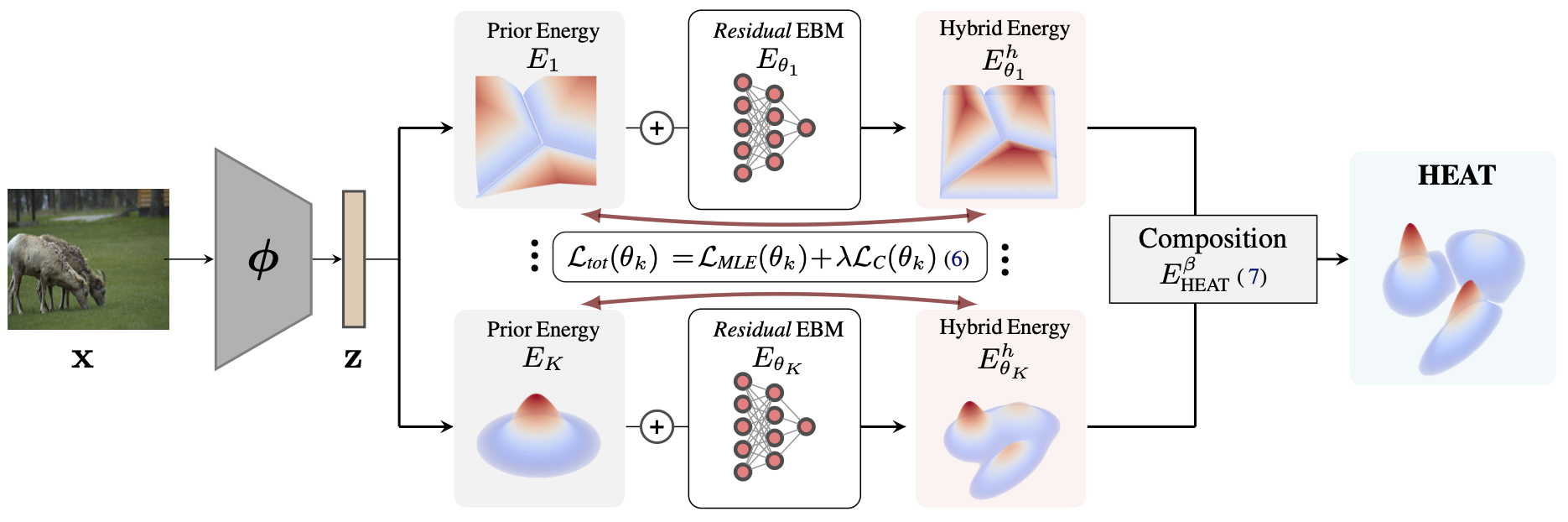
Recommended citation: Marc Lafon, Elias Ramzi, Clément Rambour, Nicolas Thome: Hybrid Energy Based Model in the Feature Space for Out-of-Distribution Detection. International Conference on Machine Learning (ICML 2023). https://arxiv.org/abs/2305.16966
Published in TMLR, 2024
Graph Neural Networks (GNNs), especially message-passing-based models, have become prominent in top-k recommendation tasks, outperforming matrix factorization models due to their ability to efficiently aggregate information from a broader context. Although GNNs are evaluated with ranking-based metrics, e.g NDCG@k and Recall@k, they remain largely trained with proxy losses, e.g the BPR loss. In this work we explore the use of ranking loss functions to directly optimize the evaluation metrics, an area not extensively investigated in the GNN community for collaborative filtering. We take advantage of smooth approximations of the rank to facilitate end-to-end training of GNNs and propose a Personalized PageRank-based negative sampling strategy tailored for ranking loss functions. Moreover, we extend the evaluation of GNN models for top-k recommendation tasks with an inductive user-centric protocol, providing a more accurate reflection of real-world applications. Our proposed method significantly outperforms the standard BPR loss and more advanced losses across four datasets and four recent GNN architectures while also exhibiting faster training. Demonstrating the potential of ranking loss functions in improving GNN training for collaborative filtering tasks.
Recommended citation: Yannis Karmim, Elias Ramzi, Raphaël Fournier-S 'Niehotta, Nicolas Thome: ITEM: Improving Training and Evaluation of Message-Passing based GNNs for top-k recommendation. TMLR (2024). https://arxiv.org/pdf/2407.07912
Published in European Conference on Computer Vision (ECCV 2024), 2024
Prompt learning has been widely adopted to efficiently adapt vision-language models (VLMs), e.g. CLIP, for few-shot image classification. Despite their success, most prompt learning methods trade-off between classification accuracy and robustness, e.g. in domain generalization or out-of-distribution (OOD) detection. In this work, we introduce Global-Local Prompts (GalLoP), a new prompt learning method that learns multiple diverse prompts leveraging both global and local visual features. The training of the local prompts relies on local features with an enhanced vision-text alignment. To focus only on pertinent features, this local alignment is coupled with a sparsity strategy in the selection of the local features. We enforce diversity on the set of prompts using a new “prompt dropout” technique and a multiscale strategy on the local prompts. GalLoP outperforms previous prompt learning methods on accuracy on eleven datasets in different few shots settings and with various backbones. Furthermore, GalLoP shows strong robustness performances in both domain generalization and OOD detection, even outperforming dedicated OOD detection methods. Code and instructions to reproduce our results: https://github.com/MarcLafon/gallop.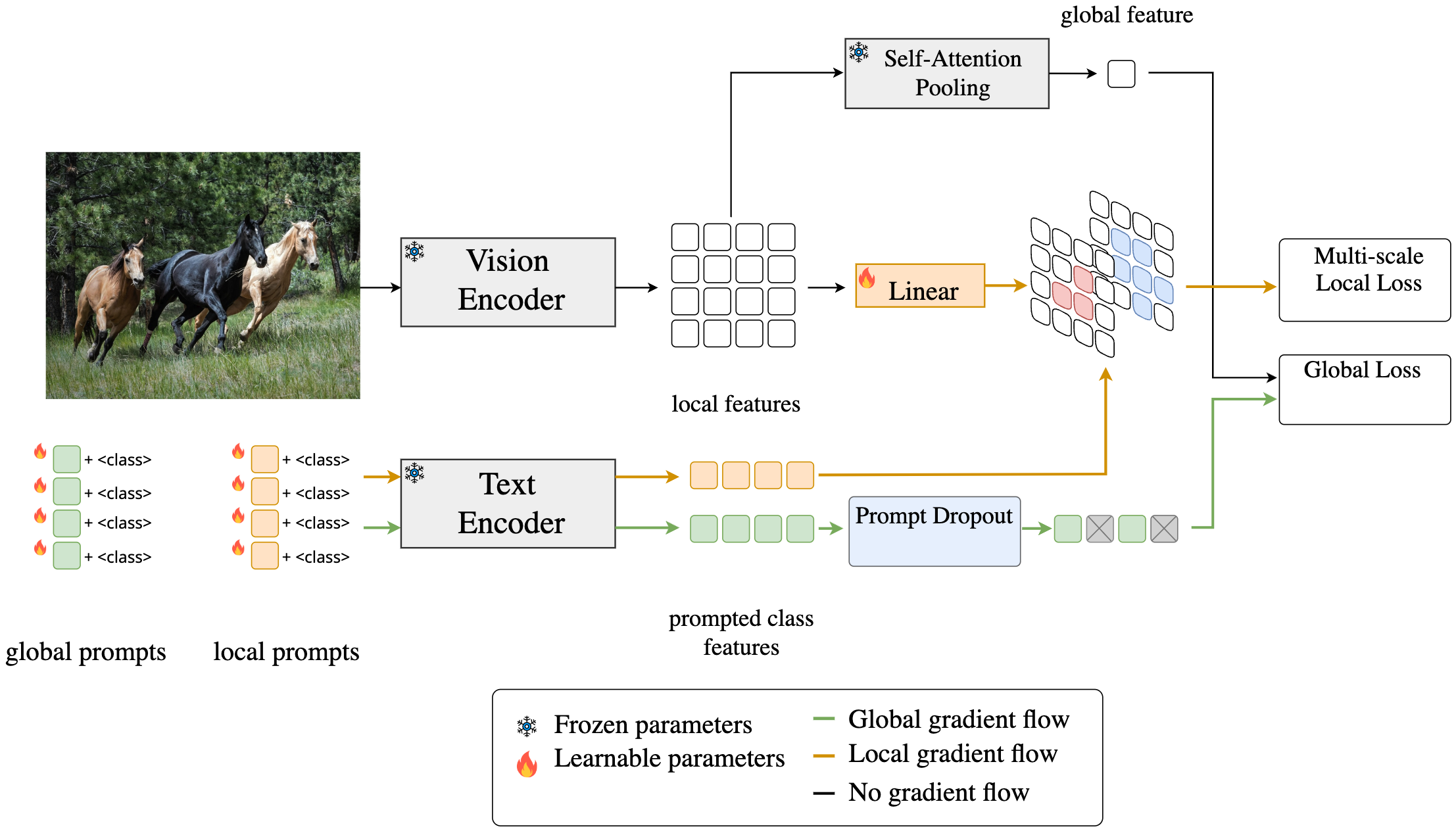
Recommended citation: Marc Lafon, Elias Ramzi, Clément Rambour, Nicolas Audebert, Nicolas Thome: GalLoP: Learning Global and Local Prompts for Vision-Language Models. European Conference on Computer Vision (ECCV 2024). https://arxiv.org/abs/2407.01400
Published in IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI, 2025), 2025
In image retrieval, standard evaluation metrics rely on score ranking, e.g. average precision (AP), recall at k (R@k), normalized discounted cumulative gain (NDCG). In this work we introduce a general framework for robust and decomposable rank losses optimization. It addresses two major challenges for end-to-end training of deep neural networks with rank losses: non-differentiability and non-decomposability. Firstly we propose a general surrogate for ranking operator, SupRank, that is amenable to stochastic gradient descent. It provides an upperbound for rank losses and ensures robust training. Secondly, we use a simple yet effective loss function to reduce the decomposability gap between the averaged batch approximation of ranking losses and their values on the whole training set. We apply our framework to two standard metrics for image retrieval: AP and R@k. Additionally we apply our framework to hierarchical image retrieval. We introduce an extension of AP, the hierarchical average precision H-AP, and optimize it as well as the NDCG. Finally we create the first hierarchical landmarks retrieval dataset. We use a semi-automatic pipeline to create hierarchical labels, extending the large scale Google Landmarks v2 dataset. The hierarchical dataset is publicly available at github.com/cvdfoundation/google-landmark. Code will be released at github.com/elias-ramzi/SupRank.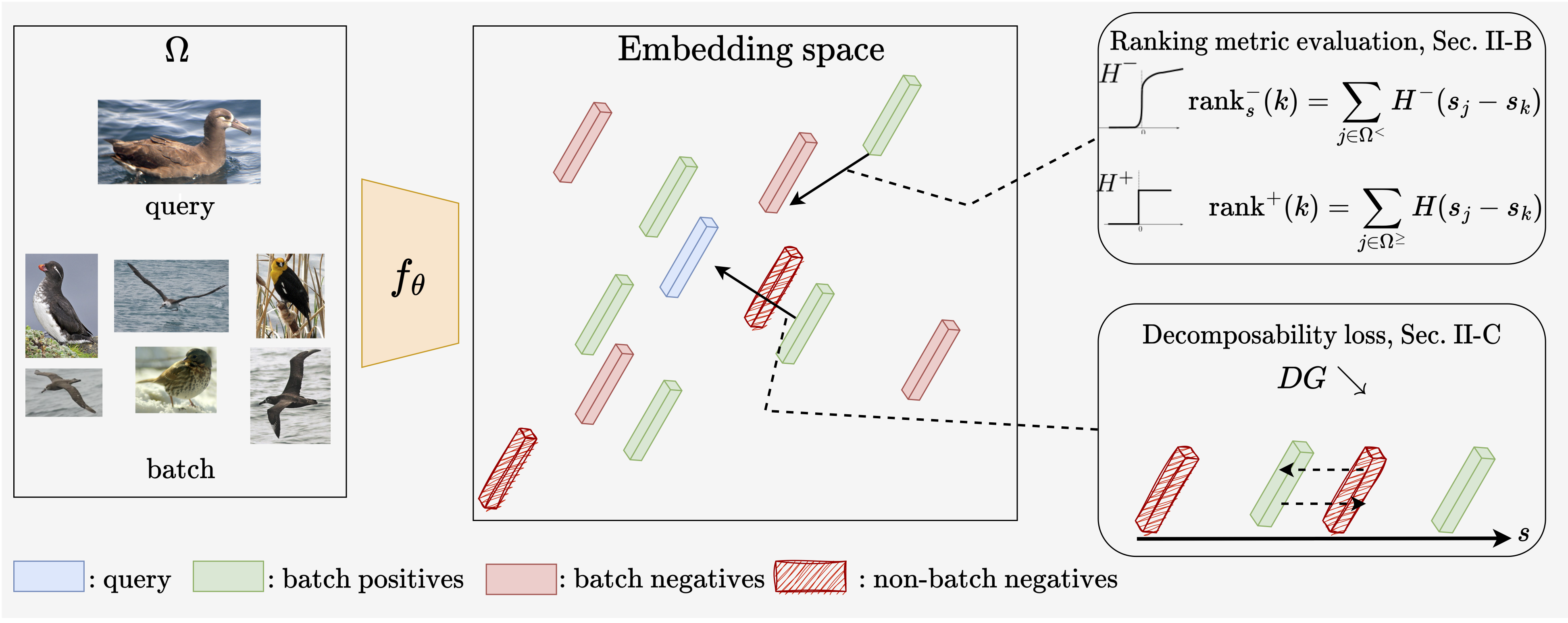
Recommended citation: Elias Ramzi, Nicolas Audebert, Clément Rambour, André Araujo, Xavier Bitot, Nicolas Thome: Optimization of Rank Losses for Image Retrieval. In IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI, 2025). https://arxiv.org/abs/2309.08250
Published in ArXiv Preprint 2025, 2025
We explore the potential of large-scale generative video models for autonomous driving, introducing an open-source auto-regressive video model (VaViM) and its companion video-action model (VaVAM) to investigate how video pre-training transfers to real-world driving. VaViM is a simple auto-regressive video model that predicts frames using spatio-temporal token sequences. We show that it captures the semantics and dynamics of driving scenes. VaVAM, the video-action model, leverages the learned representations of VaViM to generate driving trajectories through imitation learning. Together, the models form a complete perception-to-action pipeline. We evaluate our models in open- and closed-loop driving scenarios, revealing that video-based pre-training holds promise for autonomous driving. Key insights include the semantic richness of the learned representations, the benefits of scaling for video synthesis, and the complex relationship between model size, data, and safety metrics in closed-loop evaluations. We release code and model weights at https://github.com/valeoai/VideoActionModel.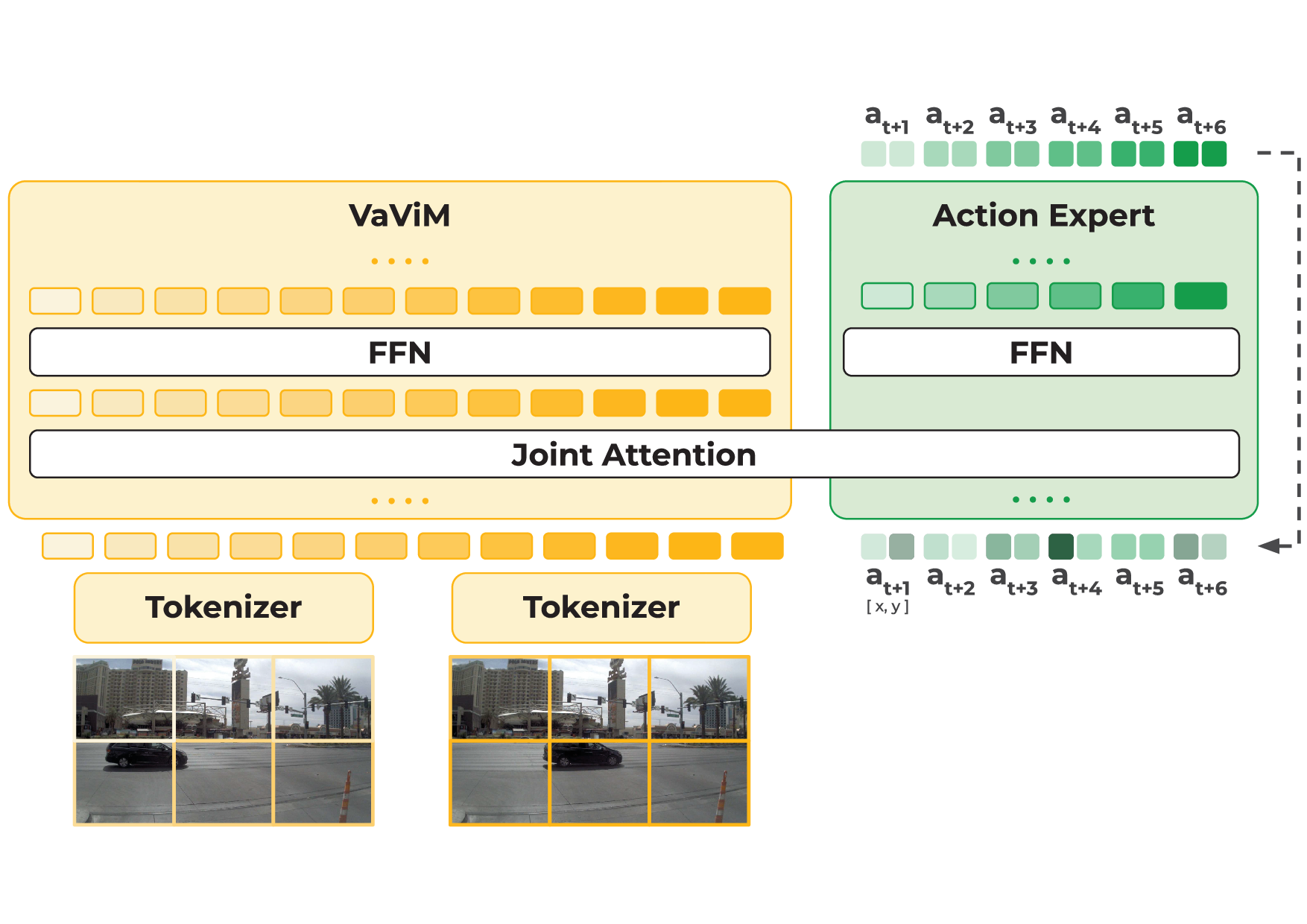
Recommended citation: Florent Bartoccioni, Elias Ramzi, Victor Besnier, Shashanka Venkataramanan, Tuan-Hung Vu, Yihong Xu, Loick Chambon, Spyros Gidaris, Serkan Odabas, David Hurych, Renaud Marlet, Alexandre Boulch, Mickael Chen, Éloi Zablocki, Andrei Bursuc, Eduardo Valle, Matthieu Cord: VaViM and VaVAM: Autonomous Driving through Video Generative Modeling. ArXiv Preprint 2025. https://arxiv.org/abs/2502.15672
Published in Internation Conference on Learning Representations (ICLR 2025), 2025
Vision Language Models (VLMs) have demonstrated remarkable capabilities in various open-vocabulary tasks, yet their zero-shot performance lags behind task-specific fine-tuned models, particularly in complex tasks like Referring Expression Comprehension (REC). Fine-tuning usually requires ‘white-box’ access to the model’s architecture and weights, which is not always feasible due to proprietary or privacy concerns. In this work, we propose LLM-wrapper, a method for ‘black-box’ adaptation of VLMs for the REC task using Large Language Models (LLMs). LLM-wrapper capitalizes on the reasoning abilities of LLMs, improved with a light fine-tuning, to select the most relevant bounding box matching the referring expression, from candidates generated by a zero-shot black-box VLM. Our approach offers several advantages: it enables the adaptation of closed-source models without needing access to their internal workings, it is versatile as it works with any VLM, it transfers to new VLMs and datasets, and it allows for the adaptation of an ensemble of VLMs. We evaluate LLM-wrapper on multiple datasets using different VLMs and LLMs, demonstrating significant performance improvements and highlighting the versatility of our method. While LLM-wrapper is not meant to directly compete with standard white-box fine-tuning, it offers a practical and effective alternative for black-box VLM adaptation. Code and checkpoints are available at https://github.com/valeoai/LLM_wrapper .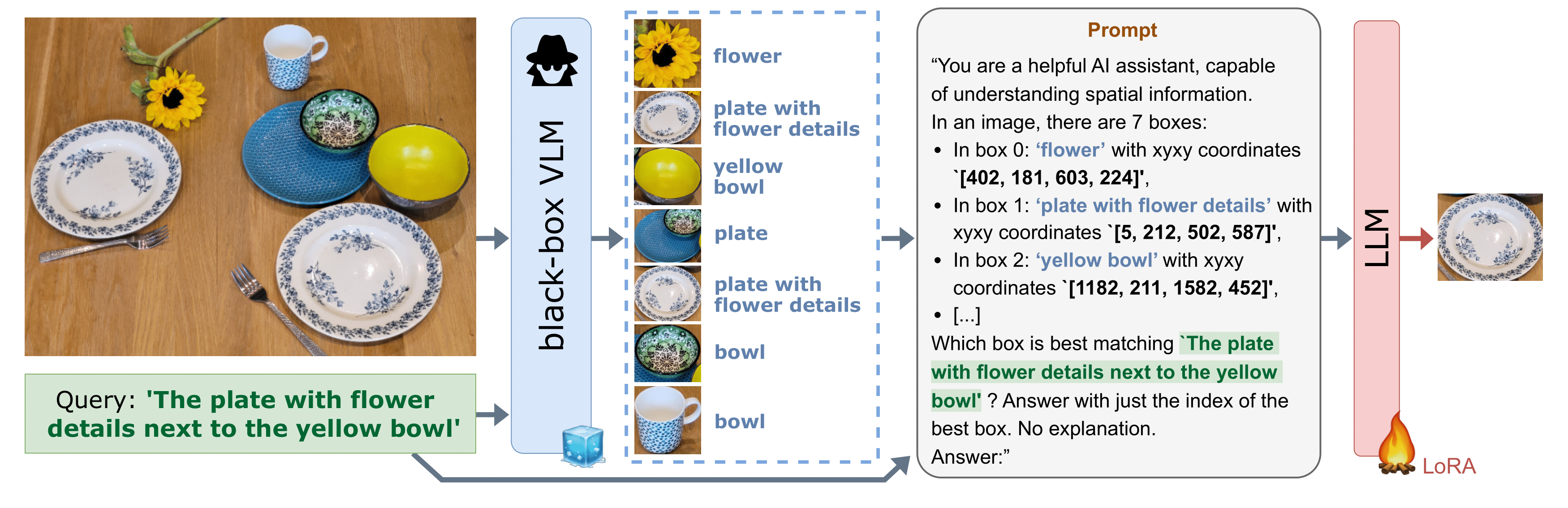
Recommended citation: Amaia Cardiel, Éloi Zablocki, Elias Ramzi, Oriane Siméoni, Matthieu Cord: LLM-wrapper: Black-Box Semantic-Aware Adaptation of Vision-Language Models for Referring Expression Comprehension. Internation Conference on Learning Representations (ICLR 2025). https://arxiv.org/pdf/2409.11919
Published in CVPR, 2025
We present Franca (pronounced Fran-ka): free one; the first fully open-source (data, code, weights) vision foundation model that matches and in many cases surpasses the performance of state-of-the-art proprietary models, e.g., DINOv2, CLIP, SigLIPv2, etc. Our approach is grounded in a transparent training pipeline inspired by Web-SSL and uses publicly available data: ImageNet-21K and a subset of ReLAION-2B. Beyond model release, we tackle critical limitations in SSL clustering methods. While modern models rely on assigning image features to large codebooks via clustering algorithms like Sinkhorn-Knopp, they fail to account for the inherent ambiguity in clustering semantics. To address this, we introduce a parameter-efficient, multi-head clustering projector based on nested Matryoshka representations. This design progressively refines features into increasingly fine-grained clusters without increasing the model size, enabling both performance and memory efficiency. Additionally, we propose a novel positional disentanglement strategy that explicitly removes positional biases from dense representations, thereby improving the encoding of semantic content. This leads to consistent gains on several downstream benchmarks, demonstrating the utility of cleaner feature spaces. Our contributions establish a new standard for transparent, high-performance vision models and open a path toward more reproducible and generalizable foundation models for the broader AI community. The code and model checkpoints are available at https://github.com/valeoai/Franca.
Recommended citation: Shashanka Venkataramanan, Valentinos Pariza, Mohammadreza Salehi, Lukas Knobel, Spyros Gidaris, Elias Ramzi, Andrei Bursuc, Yuki M. Asano: Franca: Nested Matryoshka Clustering for Scalable Visual Representation Learning. CVPR (2026). https://arxiv.org/pdf/2507.14137
Published in ACL findings, 2026
Large language models (LLMs) are increasingly used as reasoning engines in autonomous driving, yet their decision-making remains opaque. We propose to study their decision process through counterfactual explanations, which identify the minimal semantic changes to a scene description required to alter a driving plan. We introduce DRIV-EX, a method that leverages gradient-based optimization on continuous embeddings to identify the input shifts required to flip the model's decision. Crucially, to avoid the incoherent text typical of unconstrained continuous optimization, DRIV-EX uses these optimized embeddings solely as a semantic guide: they are used to bias a controlled decoding process that re-generates the original scene description. This approach effectively steers the generation toward the counterfactual target while guaranteeing the linguistic fluency, domain validity, and proximity to the original input, essential for interpretability. Evaluated using the LC-LLM planner on a textual transcription of the highD dataset, DRIV-EX generates valid, fluent counterfactuals more reliably than existing baselines. It successfully exposes latent biases and provides concrete insights to improve the robustness of LLM-based driving agents. The code is available at "https://github.com/Amaia-CARDIEL/DRIV_EX" .
Recommended citation: Amaia Cardiel, Éloi Zablocki, Elias Ramzi, Eric Gaussier: DRIV-EX: Counterfactual Explanations for Driving LLMs. ACL findings (2026). https://arxiv.org/pdf/2603.00696
Published in arXiv preprint, 2026
End-to-end planners for autonomous driving typically generate a set of candidate trajectories, score each one, and return the highest-scoring candidate. However, the scorer is applied only after the proposals are generated and cannot influence the set of trajectories: a weak set of candidates limits planning performance regardless of the scorer's quality. We instead treat the scorer as a learned trajectory-level reward function and search for trajectories that maximize it. Our method, TOAD, runs the Cross-Entropy Method at test time, warm-started from the planner's proposals. It requires no retraining and is plug-and-play for existing planners. Across six base planners, TOAD improves results on NAVSIM-v1 (94.7 PDMS), NAVSIM-v2 (56.3 EPDMS), and the closed-loop HUGSIM benchmark. The code will be made publicly available via the project page: https://valeoai.github.io/TOAD/.
Recommended citation: Yihong Xu, Éloi Zablocki, Yuan Yin, Elias Ramzi, Ellington Kirby, Alexandre Boulch, Matthieu Cord: Test-Time Trajectory Optimization for Autonomous Driving. arXiv preprint (2026). https://arxiv.org/pdf/2606.07170
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.